Machine Learning with Cats
Training an ML Model
I used Claude Code to 'vibe code' a Machine Learning model and, separately, spun up a Google Cloud project using Vertex AI AutoML to train the identical dataset and compare the results. I used the Oxford Pet IIT Dataset, stripping out everything except for cats, leaving 12 cat breeds and ~200 images per breed.
A little help from Claude
I started with the pre-trained EfficientNet-B0 at 224px, with a frozen backbone for a few epochs before unfreezing for the remaining epochs. After running training on my laptop a few weeks ago (which took around 5 hours), I opted for a GPU Instance from Lambda to speed things up.
My early runs looked promising, as training accuracy quickly shot up to ~100%, but validation accuracy lagged well behind at 60-65%, a clear sign of overfitting. The biggest challenge was frequent early-stopping. Since my validation scores weren't improving, I never made it past the frozen backbone.
In addition to the poor performance, the server I was renting had no Nvidia drivers installed, so it kept falling back to CPU.
After installing the Nvidia drivers and implementing a few regularization tricks to fight overfitting (thank you, Claude!), the model improved drastically. Here is what worked.
- Label Smoothing: Softened targets to prevent overconfidence.
- Mixup/CutMix: Blended images and labels to encourage learning of general features.
- Learning Rate Schedule: Used cosine decay with warmup for efficient training, allowing for a mix of exploratory and precise parameter updates.
- EMA: Averaged model parameters over time to stabilize training and improve final performance.
- Discriminative Learning Rate: Applied different learning rates to the pretrained backbone and new classifier head to preserve existing knowledge while adapting to the new dataset.
But what really did the trick was switching to the larger, pre-trained EfficientNetV2-S @ 320px. Since cat breed classification is a fine-grained task, the higher resolution was helpful.
With the Nvidia drivers installed and a few changes to the hyperparameters, it was time for training. I captured some of it below.
The last run hit 95% macro F1, and the confusion matrix showed strong balance across classes.
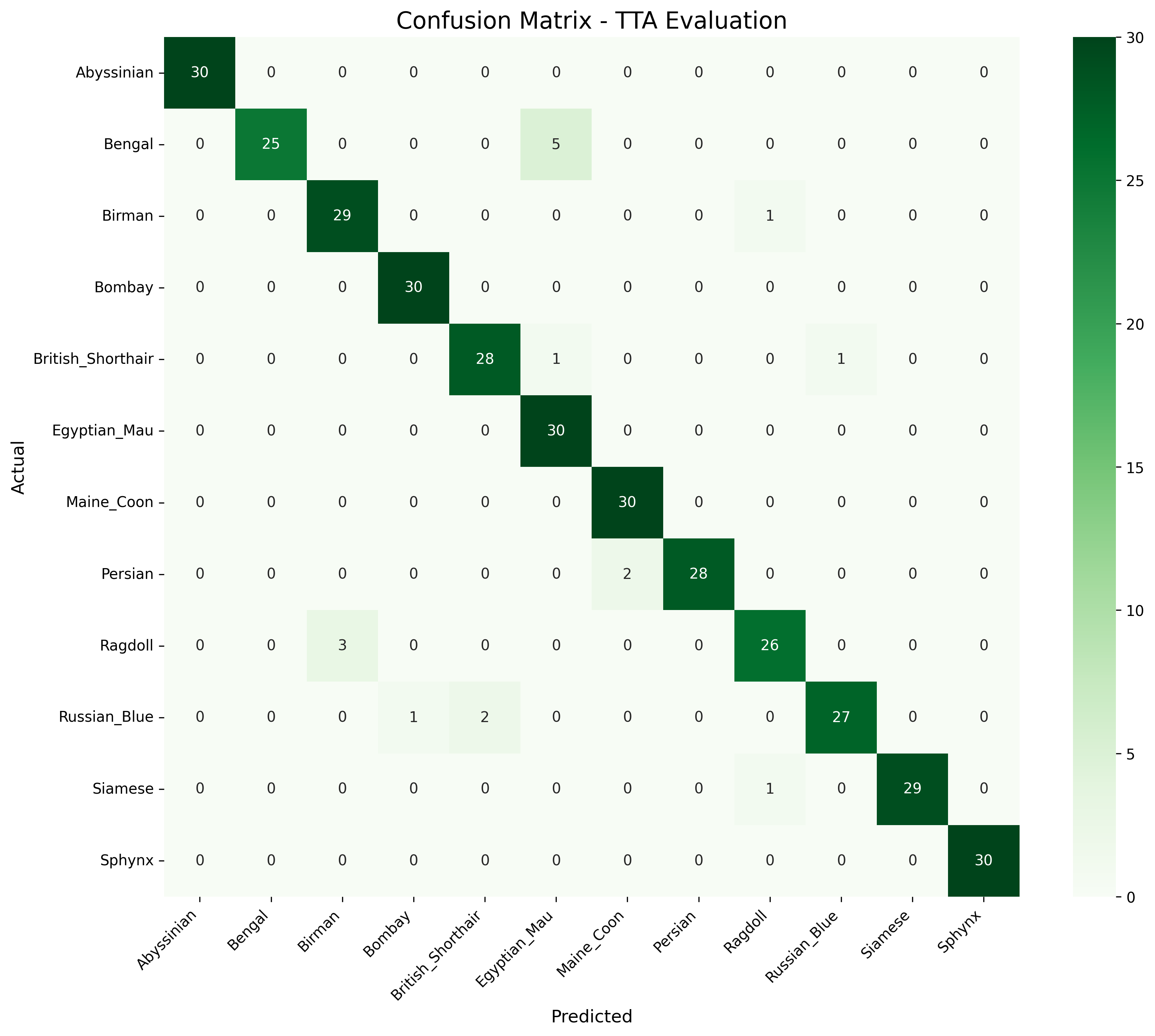
Separately, my Vertex AI AutoML training took a whopping 24 hours. The model trained entirely from scratch, but reported strong results.
- PR AUC: 0.984
- Precision: 97.3%
- Recall: 90.7%
I built a frontend if you want to try it out here.